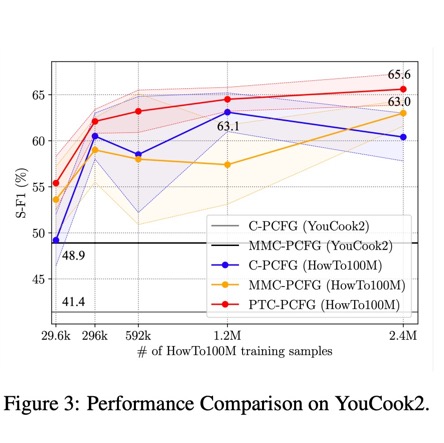
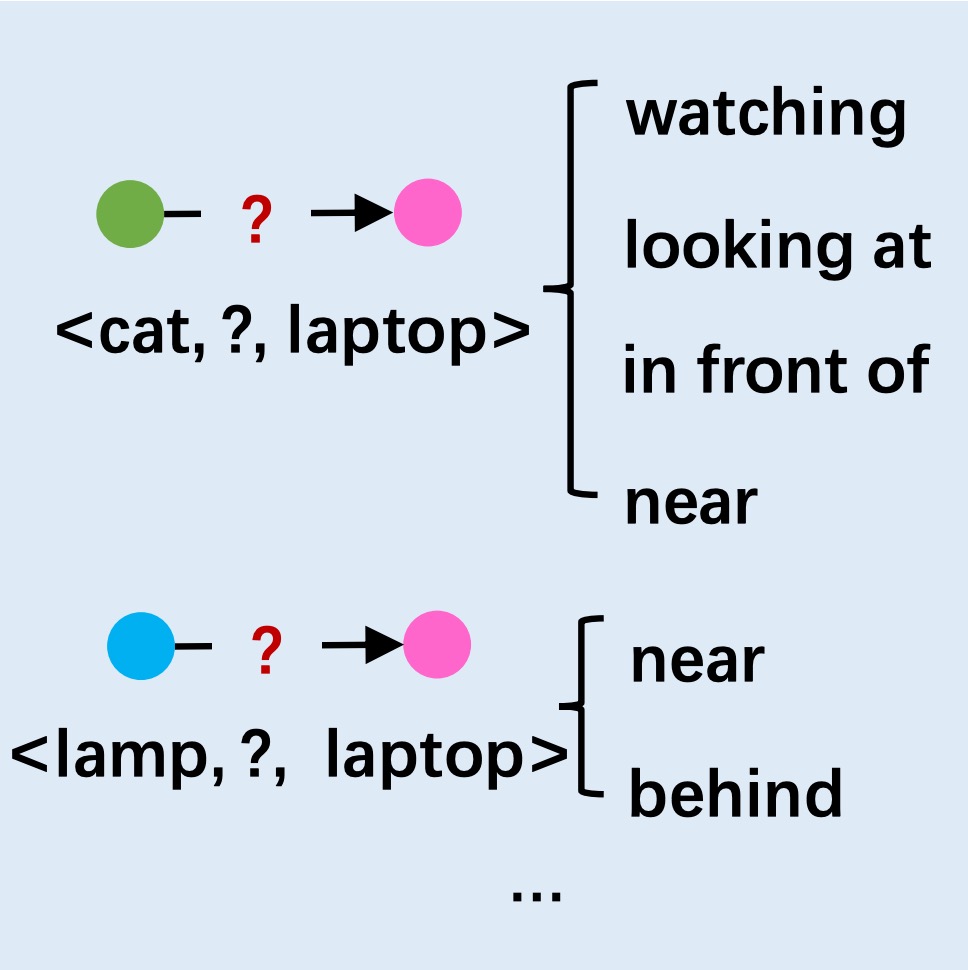
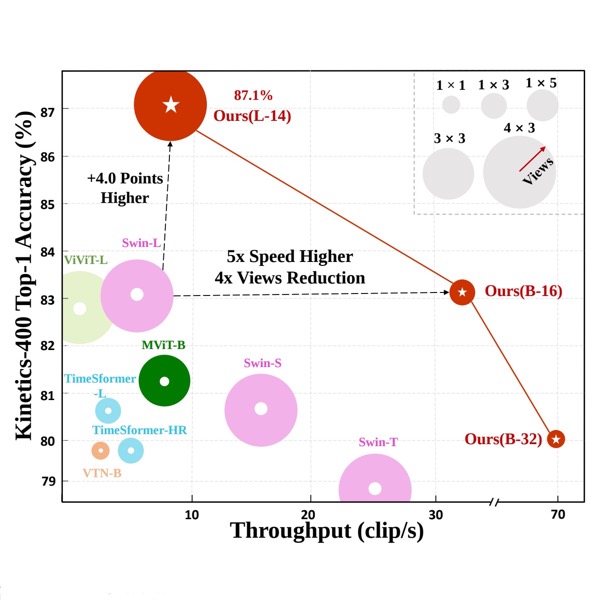
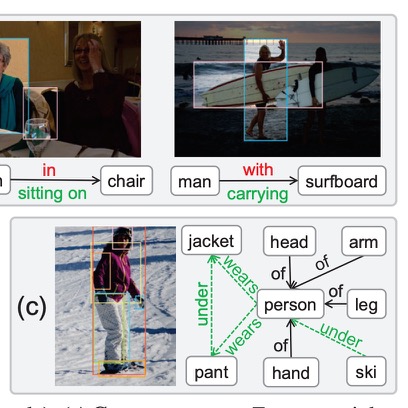
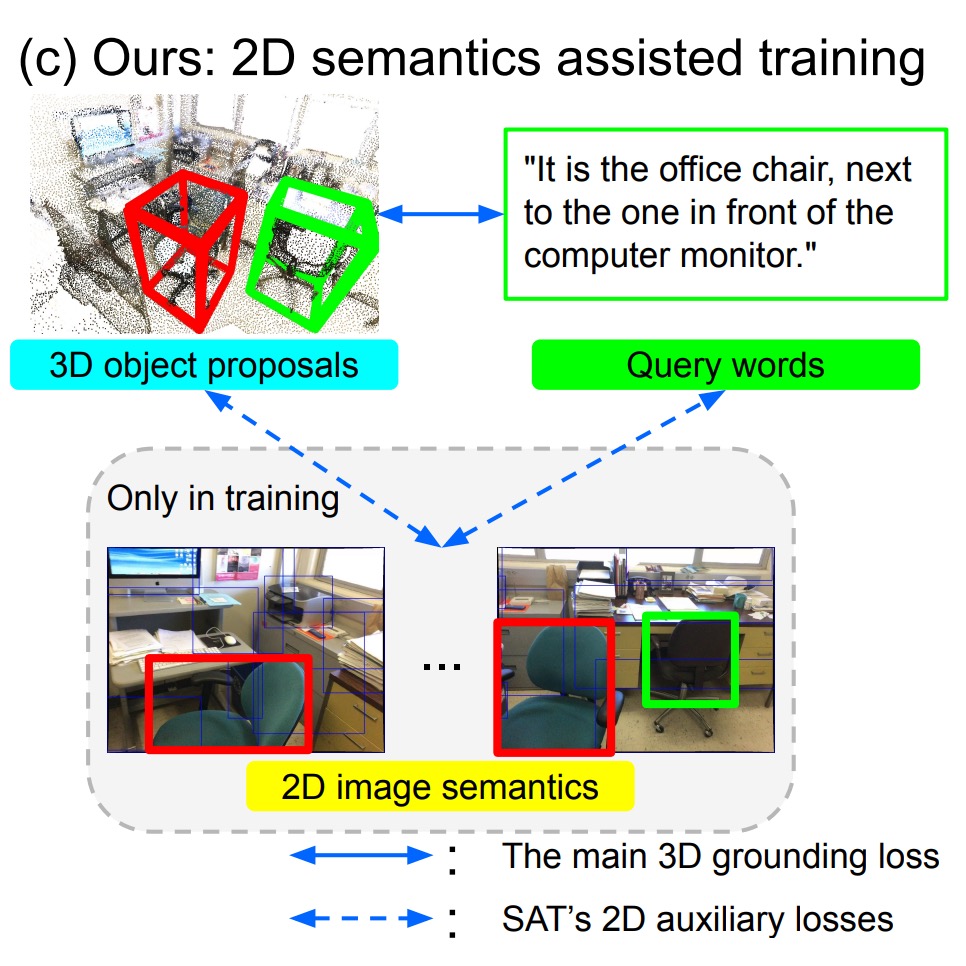
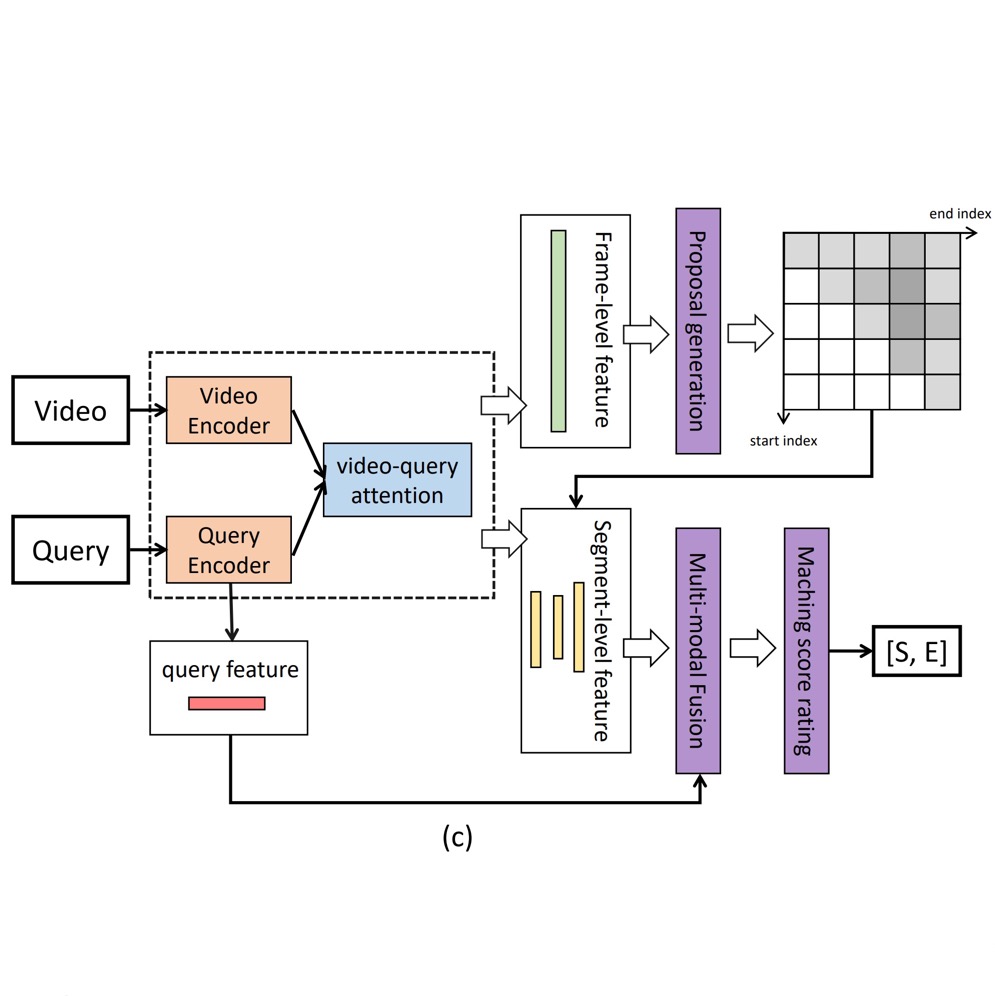
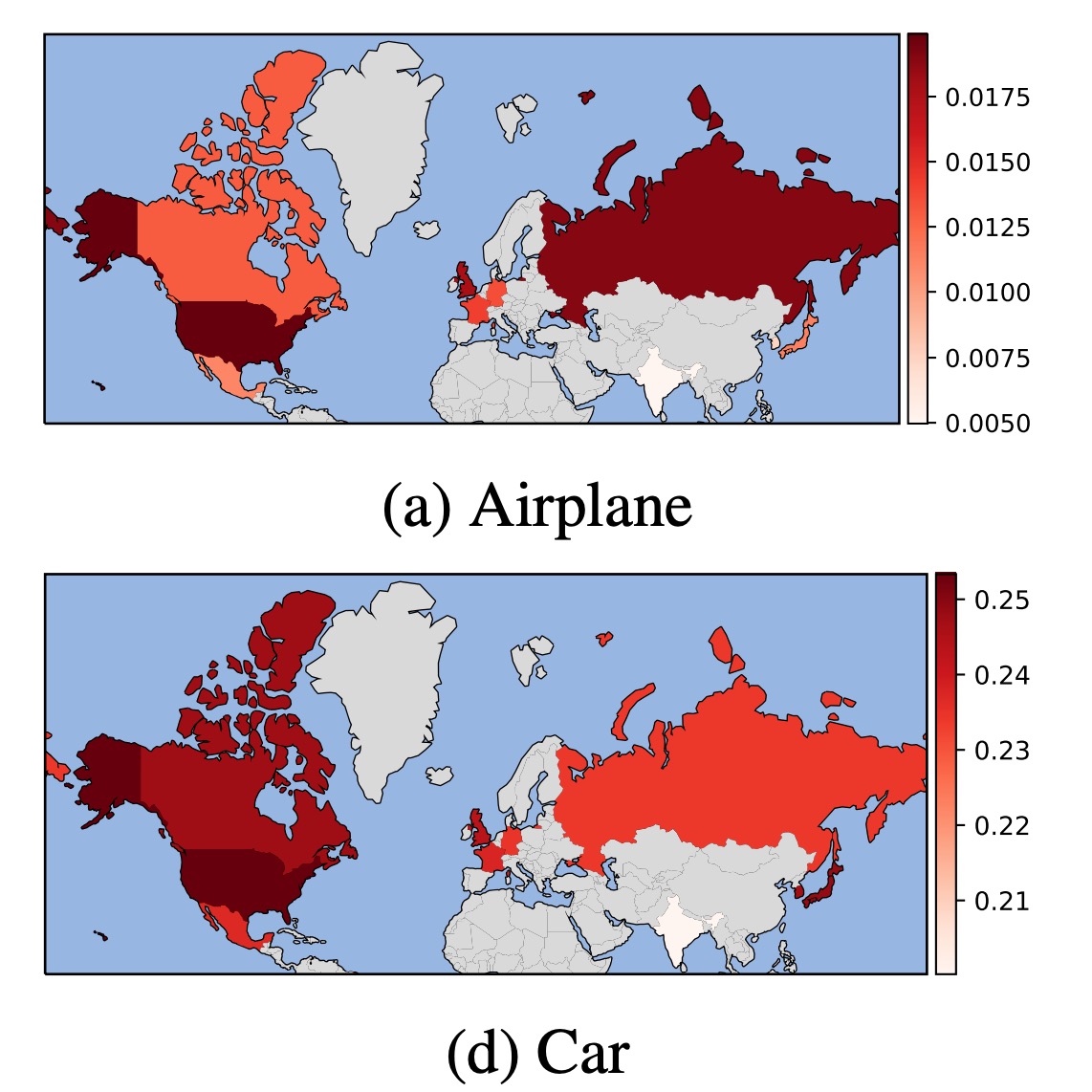
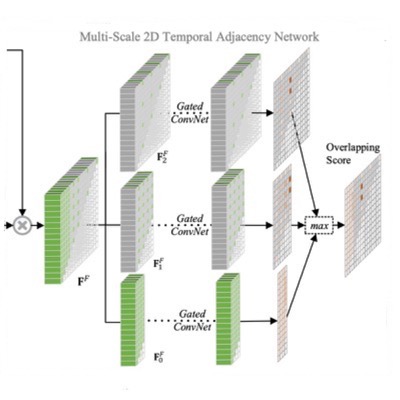
Publications
Publications by categories in reversed chronological order. * denotes equal contribution.
2024

2023
-
 Possible Worlds VQA: Cross Modality Bias Reduction in Visual Question Answering Systems from a Causal ViewIn TMM, 2023
Possible Worlds VQA: Cross Modality Bias Reduction in Visual Question Answering Systems from a Causal ViewIn TMM, 2023
Publications by categories in reversed chronological order. * denotes equal contribution.